Web crawler development – Get Started with Splash
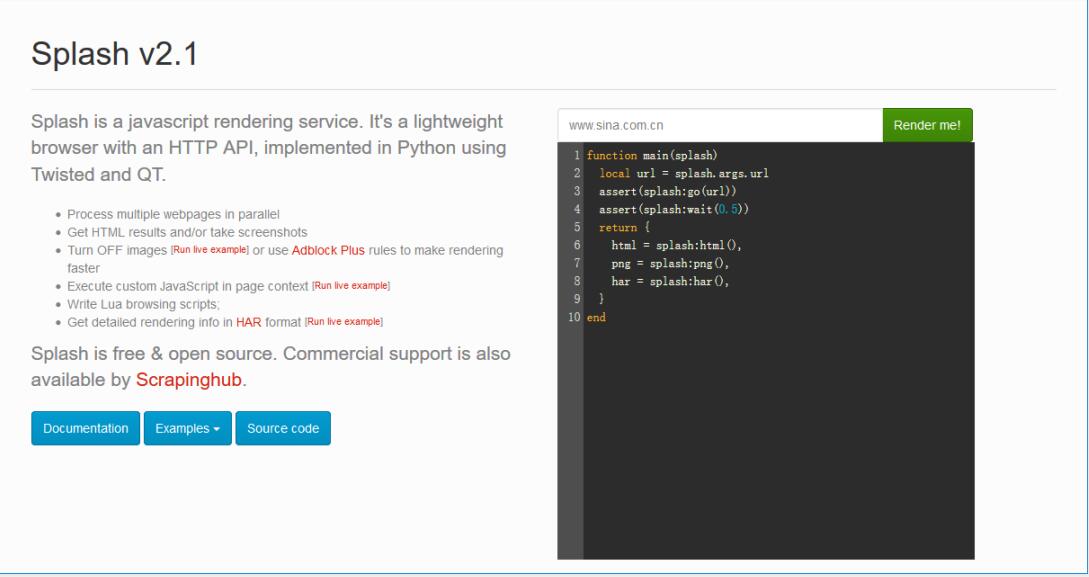
Splash is a JavaScript rendering service, a lightweight browser with an HTTP API, and it integrated with Twisted and QT libraries in Python. Using it, we can also achieve dynamic rendering pages while crawling.
Function introduction
- process multiple webpages in parallel;
- get HTML results and/or take screenshots;
- turn OFF images or use Adblock Plus rules to make rendering faster;
- execute custom JavaScript in page context;
- write Lua browsing scripts;
- develop Splash Lua scripts in Splash-Jupyter Notebooks.
- get detailed rendering info in HAR format.
Splash installation
1. Install splash service via docker
[root@master ~]# docker run -p 8050:8050 scrapinghub/splash
2. Test whether the installation is successful
Visit http://localhost: 8050/
The installation of the scrapy-splash Library
(venv) E:\WebSpider>pip install scrapy-splashExample introduction
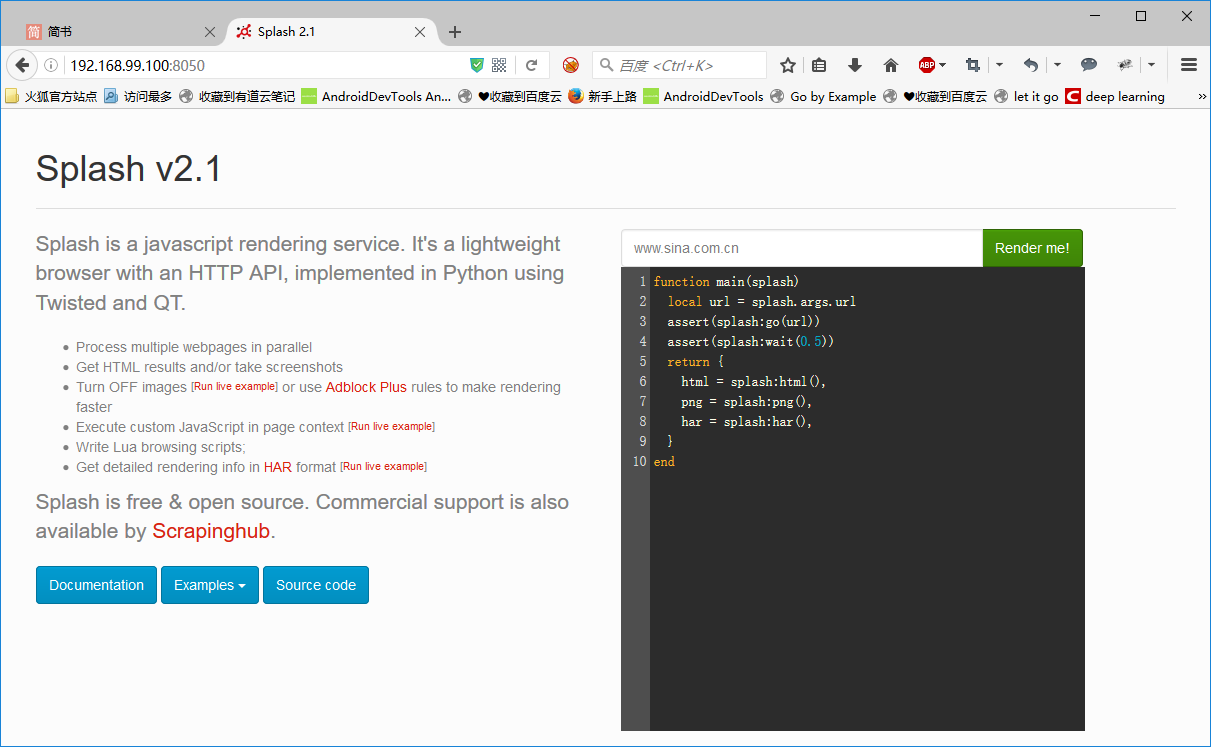
1. Test the rendering process through the web page provided by splash. For example, we run the splash service on port 8050 of our machine, and open http://localhost:8050/ to see its webpage.
2. A rendering example is presented on the right. As you can see, there is an input box above, the default is http://google.com. Here is replaced with Baidu to test, change the content to https://www.baidu.com, and then click the Render me button to start rendering.
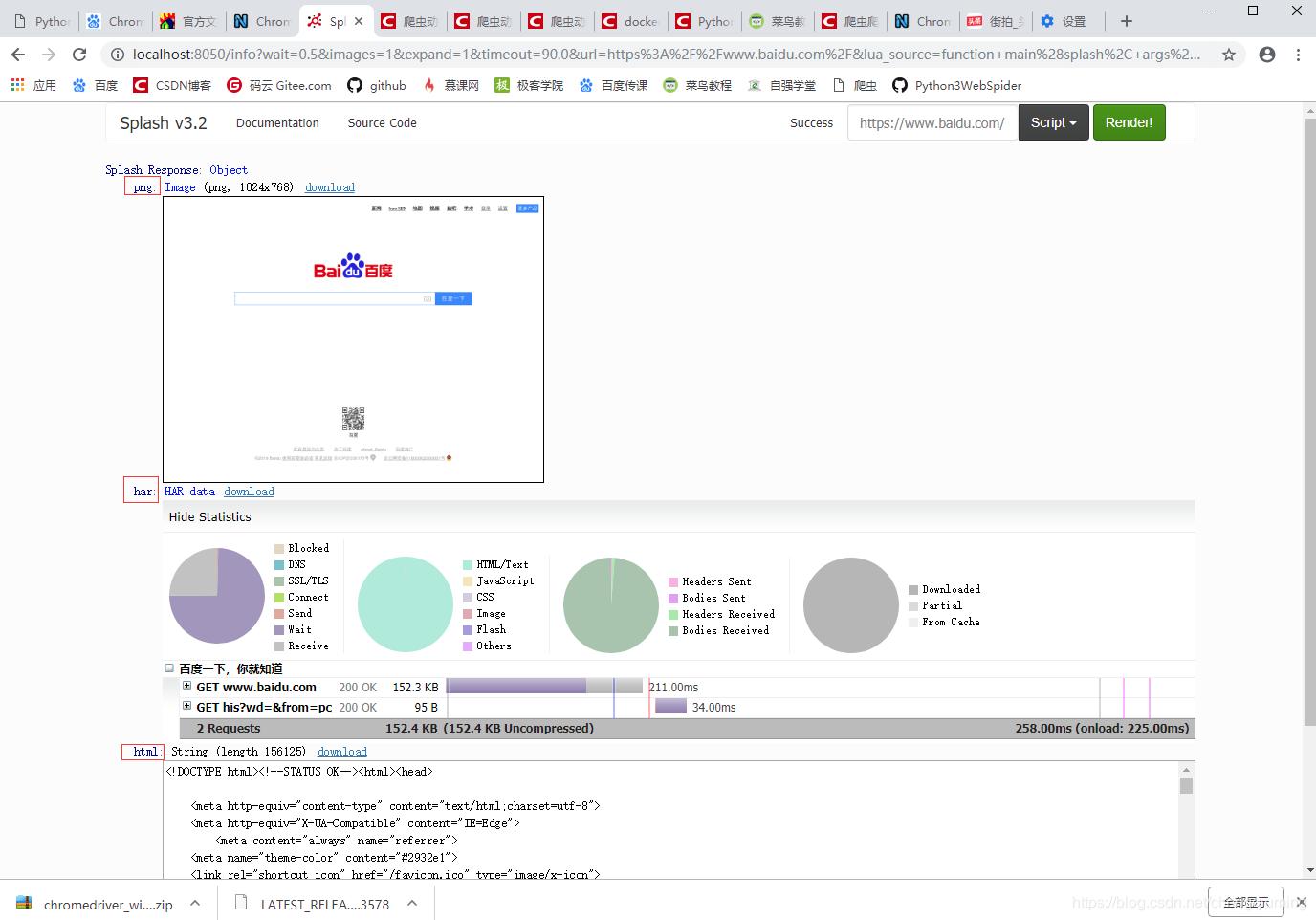
3. It can be seen that the returned result of the webpage presents the rendered screenshot, HAR loading statistics, and the source code of the webpage.
From the results of HAR, Splash performed the rendering process of the entire webpage, including the loading process of CSS and JavaScript. The rendered page is exactly the same as the result we got in the browser.
4. Script code
function main(splash, args)
assert(splash:go(args.url))
assert(splash:wait(0.5))
return {
html = splash:html(),
png = splash:png(),
har = splash:har(),
}5. Script analysis
This script is actually written in Lua. Even if we do not understand the syntax of this language, from the surface meaning of the script, we can roughly understand that it first calls the go() method to load the page, then calls the wait() method to wait for a certain time, and finally returns the source code, screenshot and HAR information.
Here, we have a general understanding that Splash controls the loading process of the page through Lua script. The loading process completely simulates the browser, and finally returns results of various formats, such as the source code and screenshots.
Splash Lua script
Splash can perform a series of rendering operations through Lua script, so that we can use Splash to simulate operations similar to Chrome and PhantomJS.
1. Entry and return values
1.1 Code
function main(splash, args)
splash:go("http://www.baidu.com")
splash:wait(0.5)
local title = splash:evaljs("document.title")
return {title=title}
end1.2 results
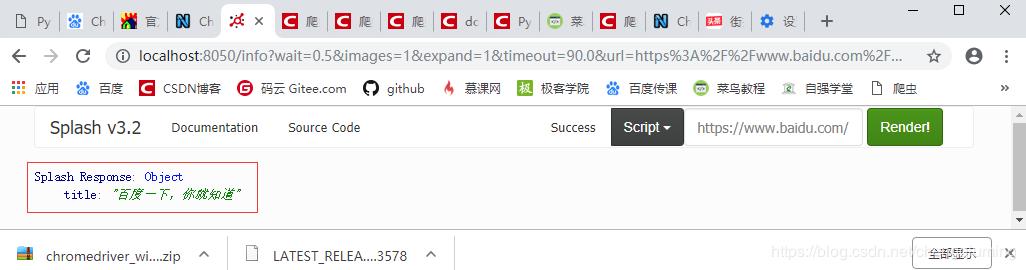
1.3 description
Notice that the method name we defined here is called main(). The name must be fixed, and Splash will call this method by default.
The return value of this method can be either in the form of a dictionary or a string, which will be converted to Splash HTTP Response in the end.
Return dictionary code:
function main(splash)
return {hello="world!"}
endReturn string:
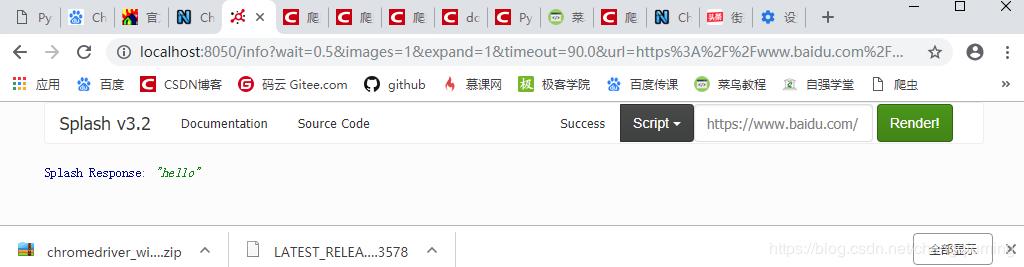
function main(splash)
return 'hello'
endresults:
1.4 asynchronous processing
Splash supports asynchronous processing, but the callback method is not explicitly specified here, and the jump of the callback is done inside Splash.
code:
function main(splash, args)
local example_urls = {"www.baidu.com", "www.taobao.com", "www.zhihu.com"}
local urls = args.urls or example_urls
local results = {}
for index, url in ipairs(urls) do
local ok, reason = splash:go("http://" .. url)
if ok then
splash:wait(2)
results[url] = splash:png()
end
end
return results
endresults:
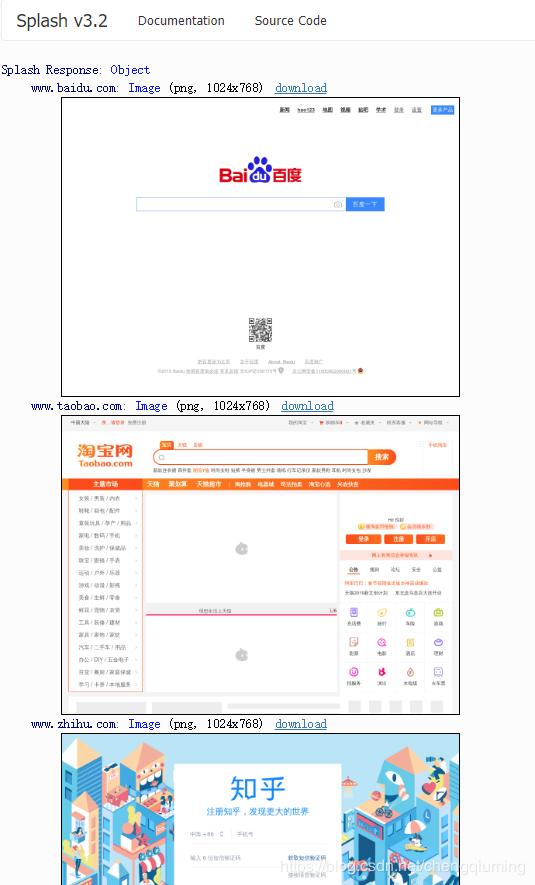
description:
The wait() method called in the script is similar to sleep() in Python, and its parameter is the number of seconds to wait. When Splash executes this method, it will turn to other tasks, and then comes back to continue processing after the specified time.
It's worth noting here that the string concatenation in Lua scripts is different from Python, which used the .. operator instead of +. If necessary, you can simply understand the syntax of Lua scripts, see http://www.lua.org/ for details.
In addition, the exception detection during loading is done here. The go() method will return the result status of the loaded page. If the page has 4xx or 5xx status code, the OK variable will be empty and the loaded image will not be returned.