Scrapy: A Python web scraping framework

A web crawler is a program that crawls data on the Internet. By using it, it can crawl HTML data of specific web pages. Although we use some libraries to develop a crawler program, the use of frameworks can greatly improve efficiency and shorten development time. Scrapy is written in Python, lightweight, simple and light, and very convenient to use.
Scrapy uses the Twisted asynchronous network library to handle network communications. The overall structure is roughly as follows:
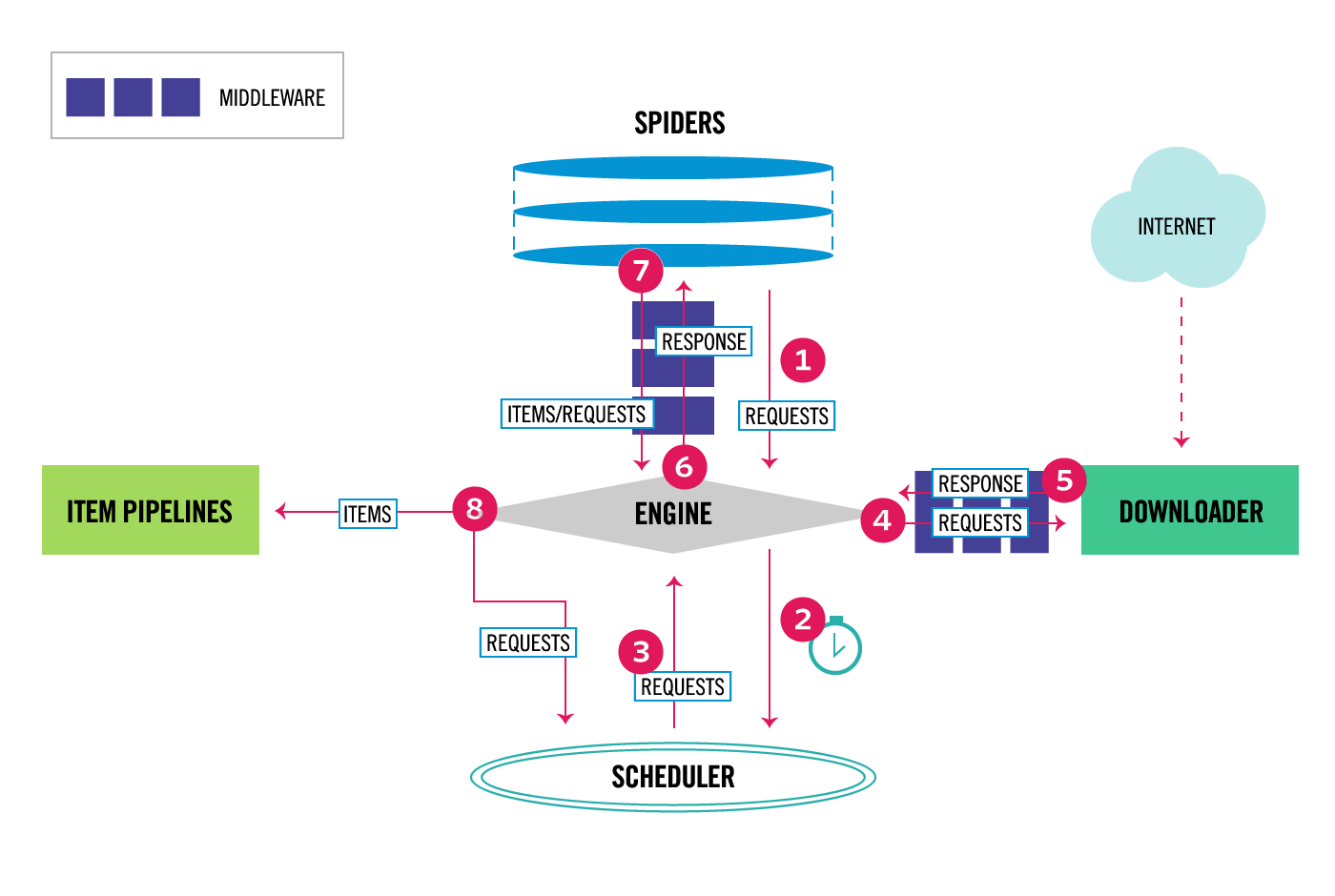
The main components of Scrapy are as follows:
1. Engine: used to process the data flow of the entire system and trigger transactions.
2. Engine: used to process the data flow of the entire system and trigger transactions.
3. Downloader: used to download webpage content and return it to spiders.
4. Spiders: spiders are mainly used to make rules for parsing specific domain names or web pages.
5. Project pipeline: responsible for processing projects extracted by spiders from web pages. Its main task is to clear, verify and store data. When the page is parsed by the spider, it will be sent to the project pipeline and processed in several specific orders.
6. Downloader middleware: The hook framework between the Scrapy engine and Downloader is mainly to handle the requests and responses between the Scrapy engine and the downloader.
7. Spider middleware: The hook framework between Scrapy engine and spider, whose main job is to handle the spider's response input and request output.
8. Scheduling middleware: The middleware between the Scrapy engine and the scheduler, sending requests and responses from the scrapy engine to the scheduler.
Using scrapy can easily complete the collection of online data on the Internet. It does a lot of work for us, you don't have to work hard to develop it yourself.