Top 10 Essential Tools For Web Crawler Engineers
We all know that workers must first sharpen their tools in order to do their best. As web crawler engineers who often have to fight with the major websites, they need to make good use of all the magic tools around them to break through the defense line of the websites. Today, I will introduce 10 tools to you through the daily crawler process. I believe that everyone will be able to improve the work efficiency by an order of magnitude after mastering them.
What does web crawler do first? Target site analysis, of course.
1. Chrome
Chrome is the basic tool of web crawler. Generally, we use it for initial crawl analysis, page logic jump, simple JS debugging, and network request steps, etc. Most of our initial work was done on it. To make an inappropriate analogy, without Chrome, we would go back from the smart era of intelligence to the horse-drawn carriage era.
2. Charles
Charles corresponds to Chrome, but it is used to do network analysis on the APP side. Compared with web side, the network analysis on the APP side is simpler, focusing on analyzing the parameters of each network request. Of course, if the other side has done parameter encryption on the server side, then it involves knowledge of reverse engineering, and that piece is a big basket of tools, we'll talk about that later.
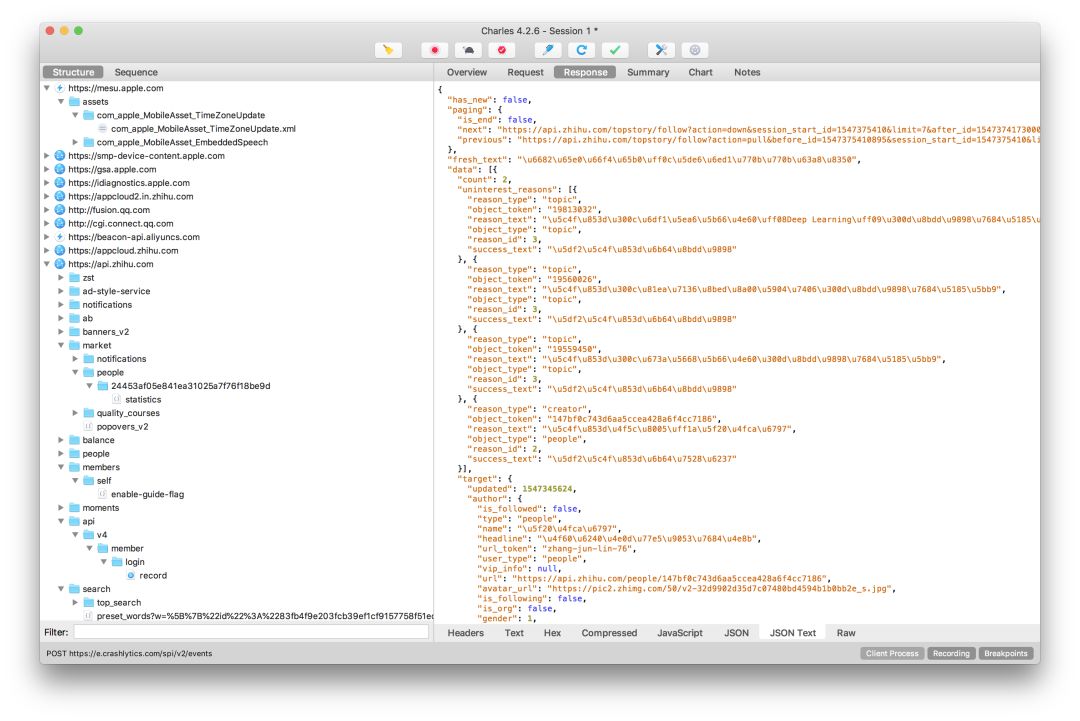
Similar tools: Fiddler, Wireshark, anyproxy.
Next, analyze the site's anti-spider.
3. cUrl
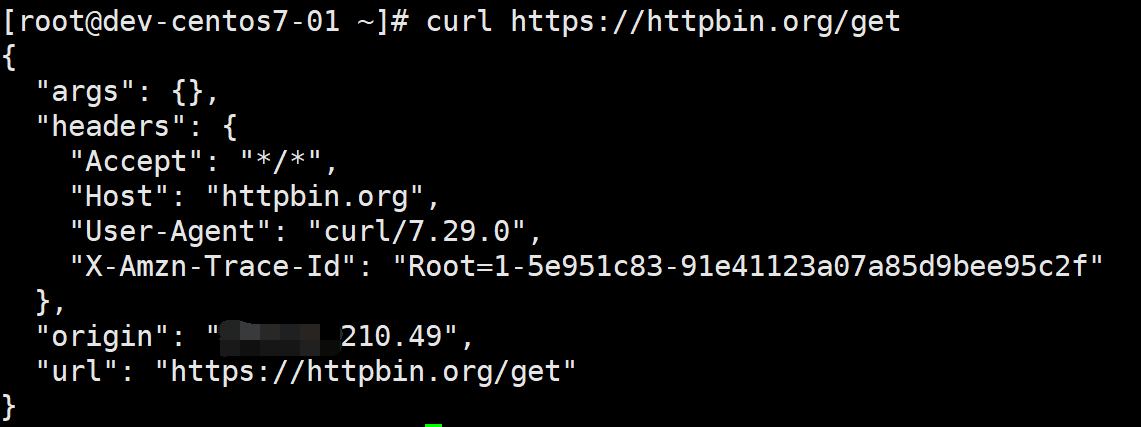
Wikipedia introduces it like this:
cURL is a file transfer tool that uses URL syntax to work on the command line. It was first released in 1997. It supports file uploading and downloading, so it's a comprehensive transmission tool, but cURL is traditionally known as a downloading tool. cURL also contains libcurl for program development.
When doing crawler analysis, we often need to simulate the request. At this time, if we write a piece of code, It's too trivial. Just copy a cURL through chrome and run in the command line to see the result.
4. Postman
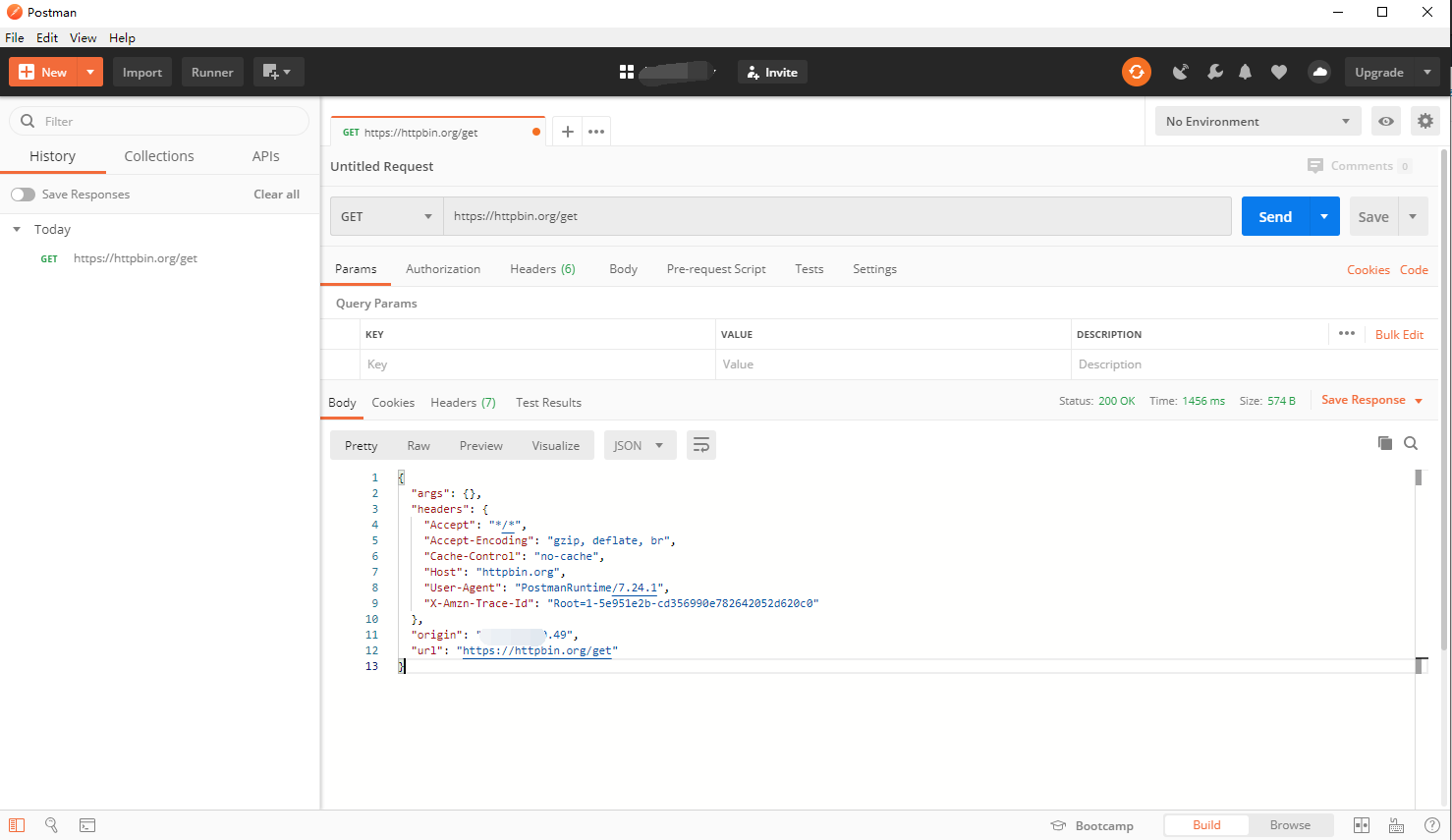
Of course, most websites don't get their data by copying the cURL link and then changing some parameters. So, we need to use the Postman as a "big killer" for a deeper analysis . Why is it a "big killer"? Because it's really powerful. With cURL, we can directly migrate the requested content, and then transform the request. Check the box to select the content parameters we want, very elegant.
5. Online JavaScript Beautifier
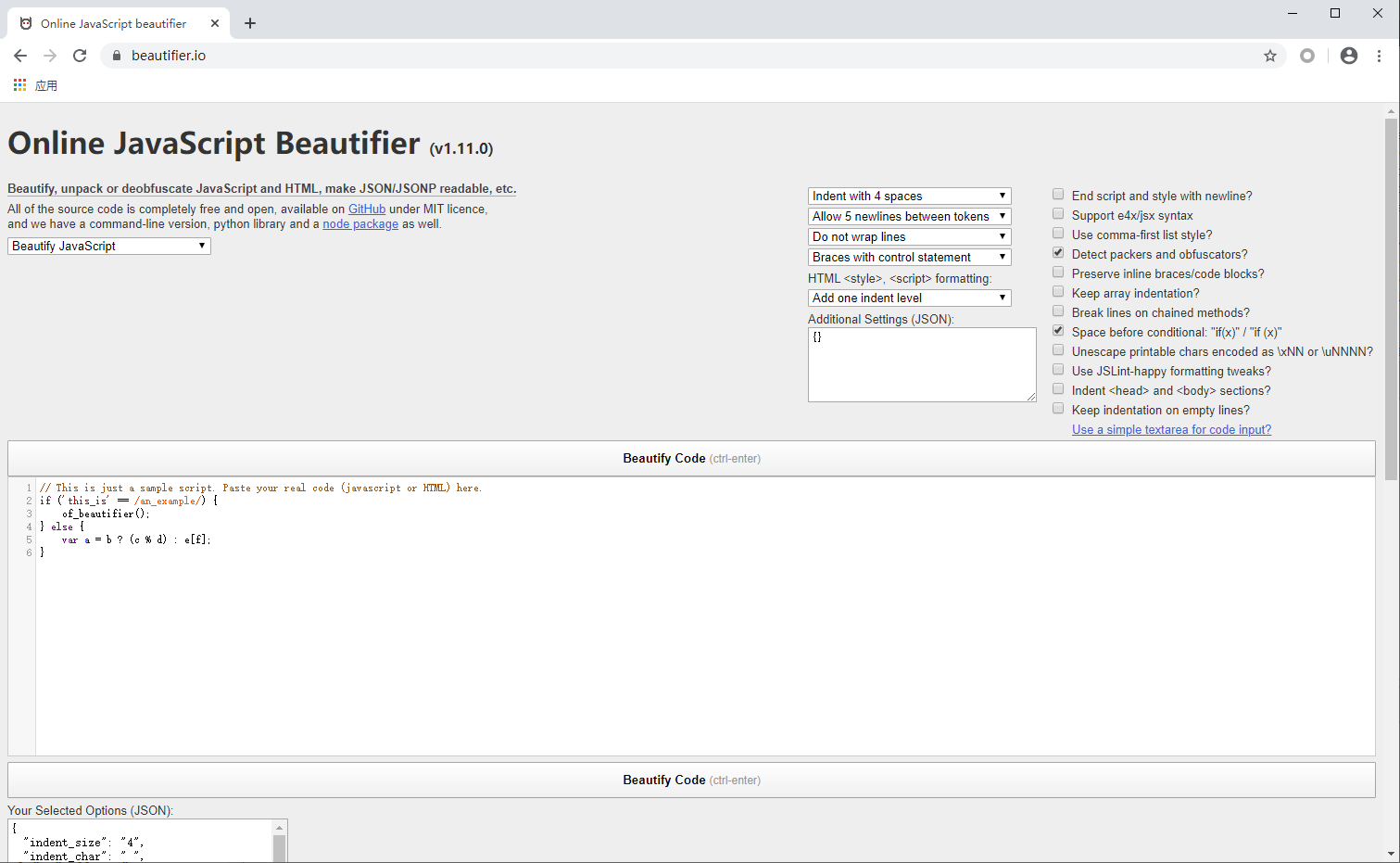
With the above tools, you can basically solve most of the websites. be considered a qualified junior crawler engineer. At this time, we need to face more complicated website crawlers if we want to advance. At this stage, you not only need to know the back-end knowledge, but also need to know some front-end knowledge, because many website anti-spider measures are put on the front-end. You need to extract the JS information of the target site, and need to reverse it and figure it out. The native JS code is generally not easy to read, it's necessary to use it to format the code for you!
Web crawlers and anti-spiders are a tug-of-war without gunsmoke. You never know which pits the other party will bury for you, such as fighting with cookies. At this time, you need it to assist your analysis. After installing the EditThisCookie plugin through Chrome, we can greatly improve the simulation of Cookies by clicking on the small icon in the upper right corner, and then adding, deleting and checking the information in Cookies.
7. The Sketch
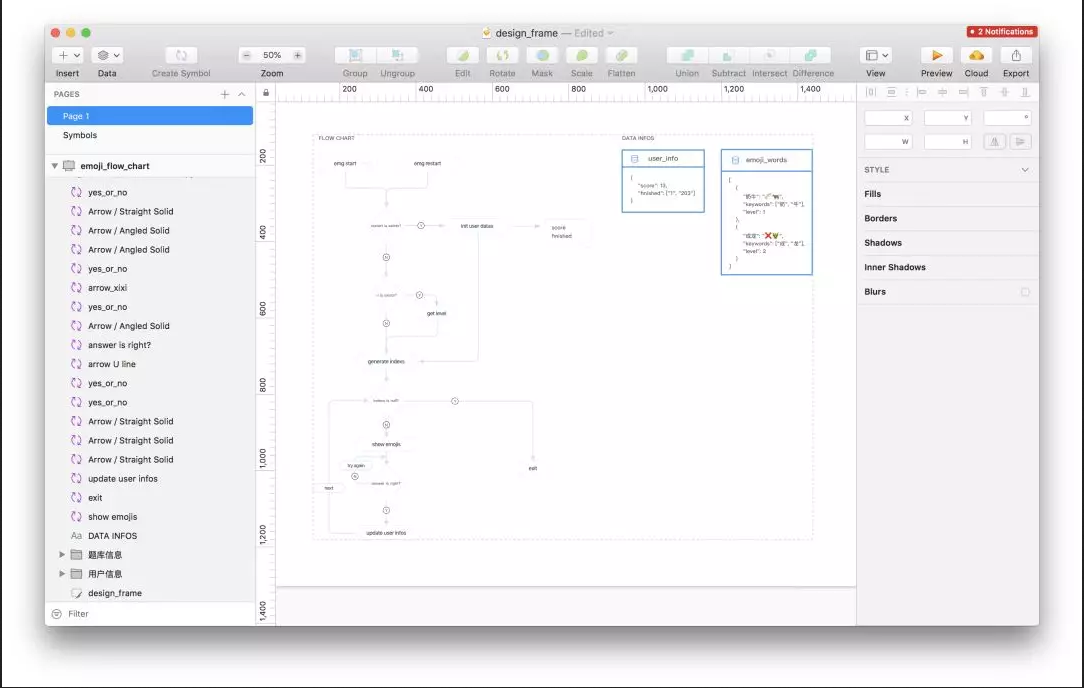
When we are sure we can crawl, we should not rush to hand-write the crawler. Instead, we should start to design the structure of the crawler. According to the needs of the business, we can do a simple crawling analysis, which will help us to develop the efficiency later, the so-called “Sharpening your ax will not delay your job of cutting wood” is this truth. For example, can we considerr wether it is search crawling or traverse crawling? Use BFS or DFS? What is the approximate number of concurrent requests? After considering these issues, we can use Sketch to draw a simple architecture diagram.
Similar tools:Illustrator, Photoshop
Start a happy crawler development journey
Finally, we are ready to start development. After the above steps, we have reached this point, and everything is ready. At this time, we just need to do code and data extraction.
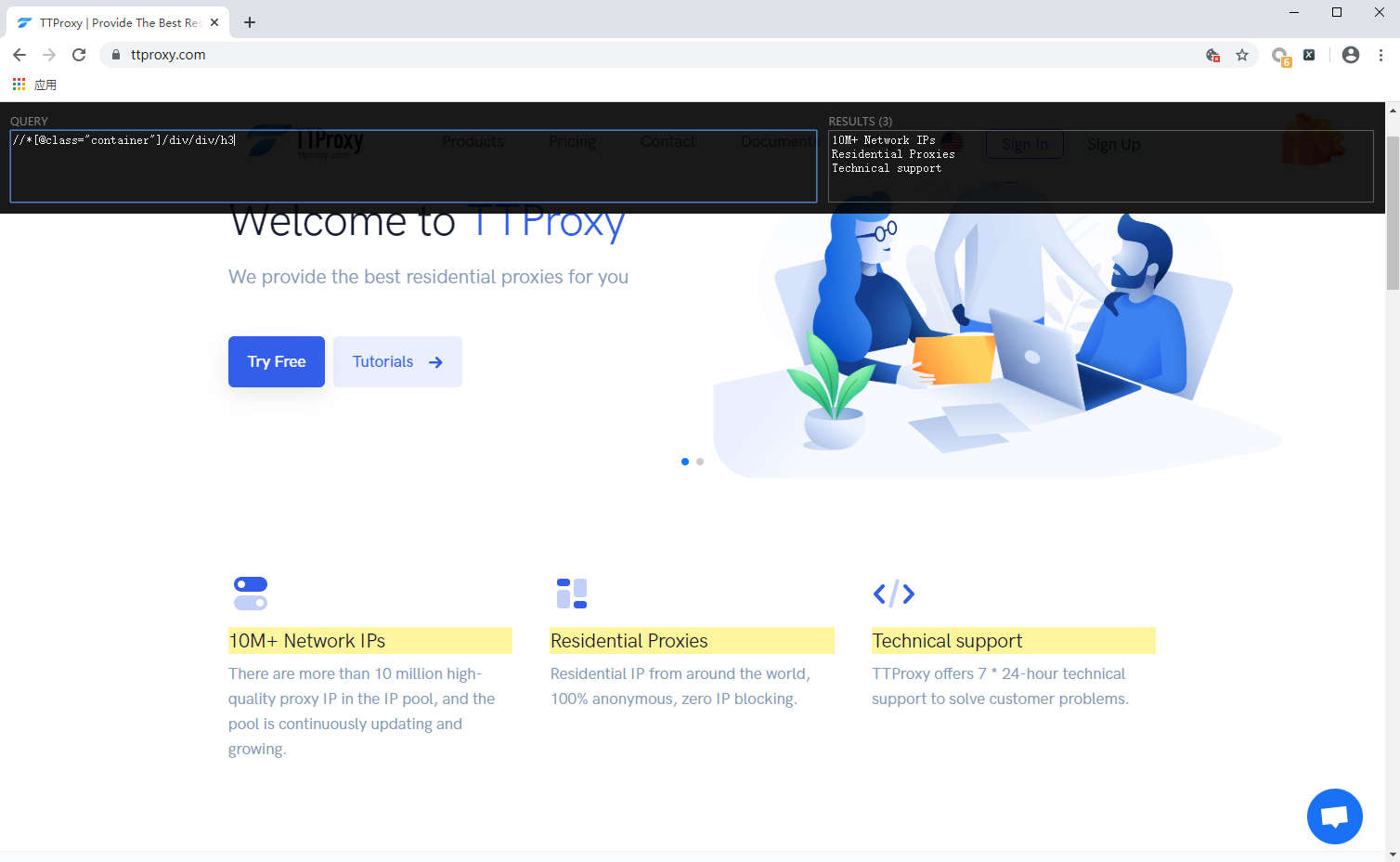
8. XPath Helper
When extracting web page data, we usually need to use xpath syntax to extract the page data information. Generally, we can only write the syntax, send a request to the other party's web pages, and then print it out, just know whether the data we extracted is correct.n the other hand, also waste our time. This is where the XPath Helper comes in. After installing the plugin through Chrome, we simply click on it to write the syntax in the corresponding XPath and see our results directly on the right...
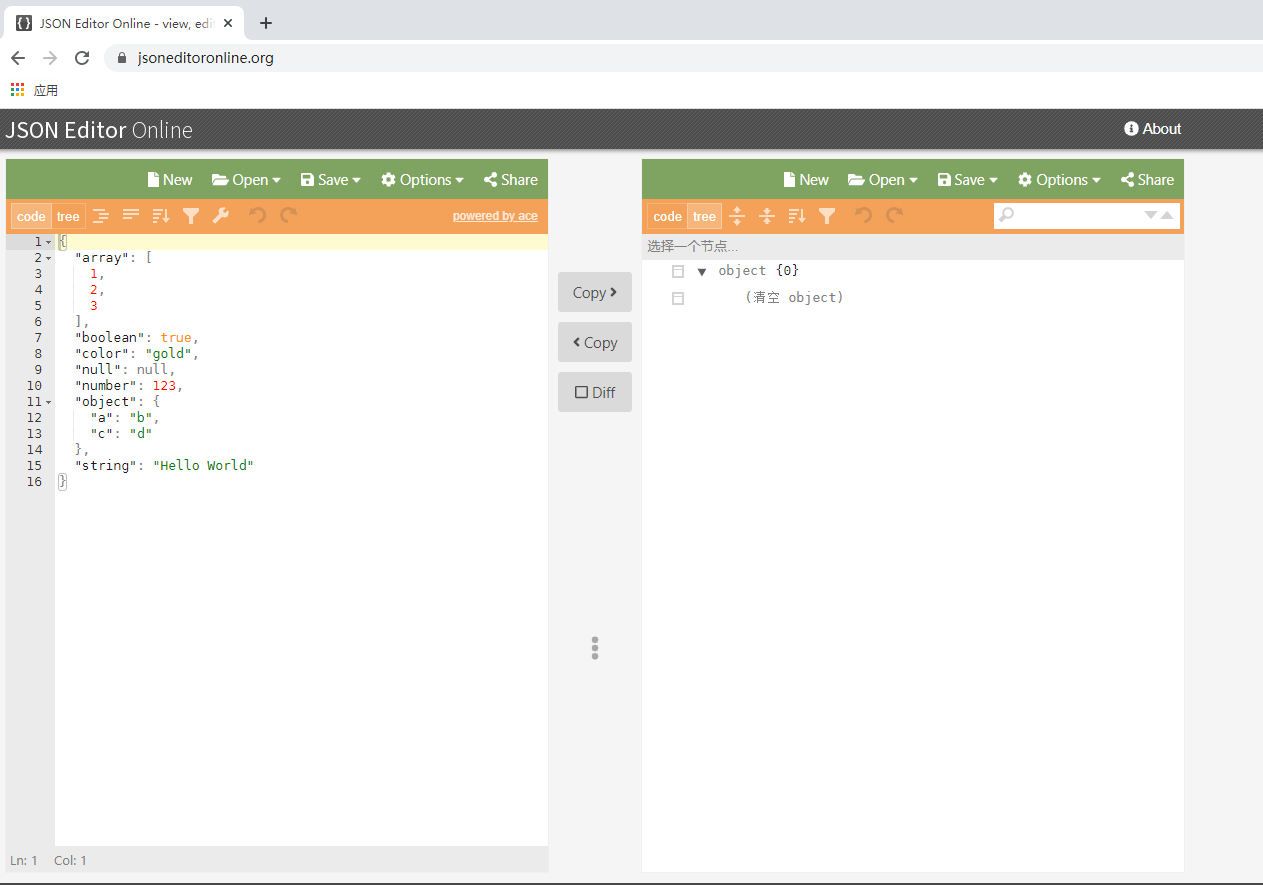
JSONView is the data returned directly on the webpage side is Json, but most of the time the results we request are HTML webpage data after the front-end rendering. The json data obtained after we initiate the request is not very good in the terminal What about the presentation of With the help of JSON Editor Online, you can format your data very well, format it in one second, and realize the intimate folding Json data function. Since seeing this, I believe you must be a true fan, and I will send you an egg tool.
10. ScreenFloat
What can it do? As the name implies, it is a screen hovering tool. However, I recently discovered that it is particularly important. Especially when we need to analyze parameters, we often need to switch back and forth on several interfaces. At this time, there are some parameters. We need to compare their differences. At this time, you can float through it first, without switching in several interfaces. Very convenient.