Introduction to Web Scraping using Selenium

What is Web Scraping?
As the name suggests, this is a technique used for extracting data from websites. It is an automated process where an application processes the HTML of a Web Page to extract data for manipulation such as converting the Web page to another format and copying itinto a local database or spreadsheet for later retrieval or analysis.
Uses Cases of Web Scraping:
There are many uses for Web Scraping but I will mention just a few:
- Contact Scraping
- Data Mining
- Online Price Change Monitoring & Price Comparison
- Product Review Scraping: to watch your competition
- Gathering Real Estate Listings
- Weather Data Monitoring
- Website Change Detection
- Research
- Tracking Online Presence and Reputation
- Web Data Integration
What is Selenium?
Selenium is a Web Browser Automation Tool.
Primarily, it is for automating web applications for testing purposes, but is certainly not limited to just that. It allows you to open a browser of your choice & perform tasks as a human being would, such as:
- Clicking buttons
- Entering information in forms
- Searching for specific information on the web pages
Point To Note
It is important to note that Web scraping is against most websites’ terms of service. Your IP address may be banned from a website if you scrape too frequently or maliciously.
What will we build?
In this tutorial we will build a web scraping program that will scrape a Github user profile and get the Repository Names and the Languages for the Pinned Repositories.
If you would like to jump straight into the project, here is link to the repo on Github.
https://github.com/TheDancerCodes/Selenium-Webscraping-Example
What will we require?
For this project we will use Python3.x. You can also use Python2.x but there may be some slight differences in the code.
NB: If you have Python 2 >=2.7.9 or Python 3 >=3.4 installed from python.org, you will already have pipinstalled.
We will also use the following packages and driver.
- selenium package —used to automate web browser interaction from Python
- ChromeDriver— provides a platform to launch and perform tasks in specified browser.
- Virtualenv — to create an isolated Python environment for our project.
- Extras: Selenium-Python ReadTheDocs Resource.
Project SetUp
Create a new project folder. Within that folder create an setup.py file. In this file, type in our dependency selenium.
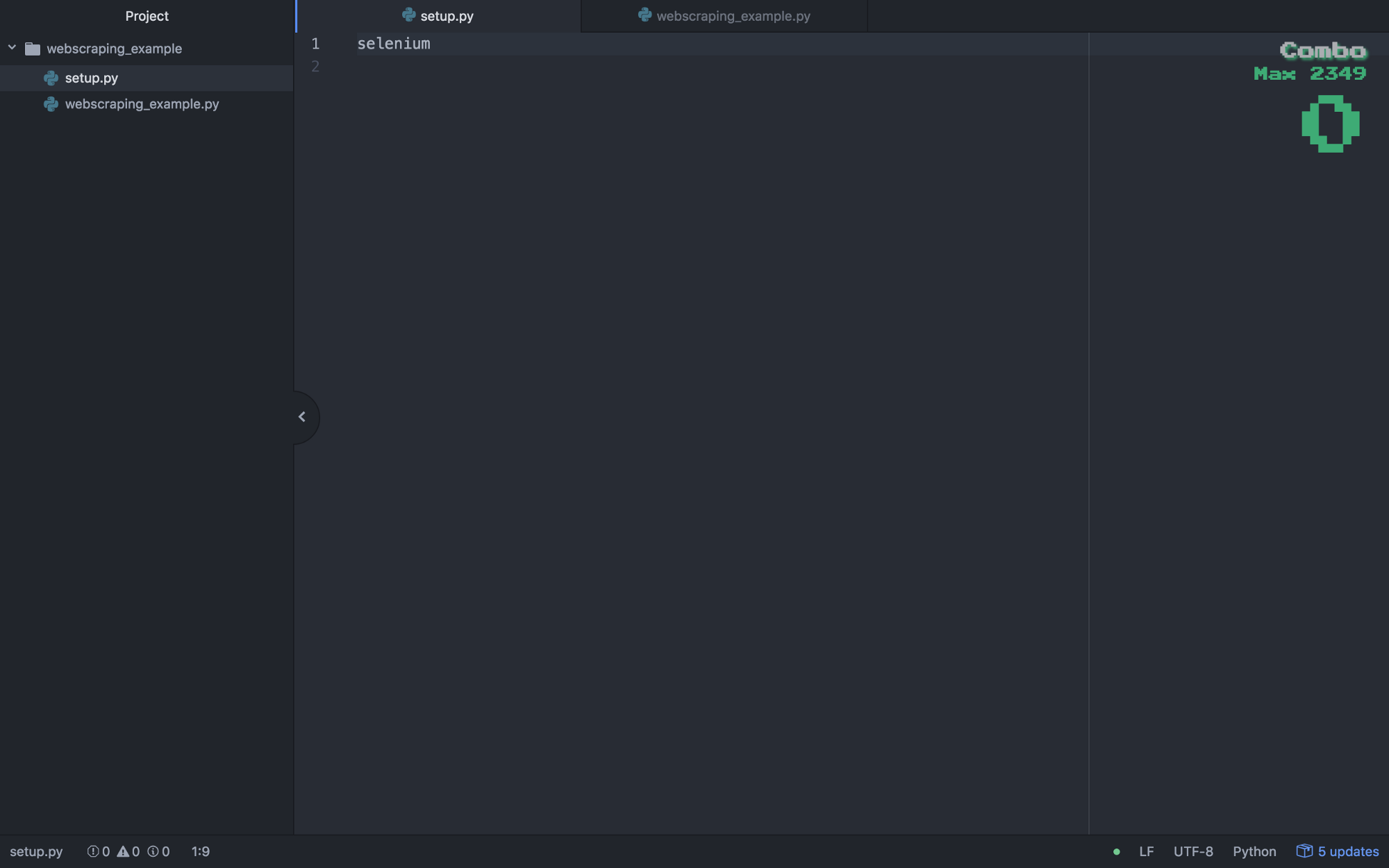
Open up your command line & create a virtual environment using the basic command:
$ virtualenv webscraping_exampleNext, install the dependency into your virtualenv by running the following command in the terminal:
$(webscraping_example) pip install -r setup.pyImport Required Modules
Within the folder we created earlier, create a webscraping_example.py file and include the following code snippets.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException- 1st import: Allows you to launch/initialise a browser.
- 2nd import: Allows you to search for things using specific parameters.
- 3rd import: Allows you to wait for a page to load.
- 4th import: Specify what you are looking for on a specific page in order to determine that the webpage has loaded.
- 5th import: Handling a timeout situation.
Create new instance of Chrome in Incognito mode
Create new instance of Chrome in Incognito mode
option = webdriver.ChromeOptions()
option.add_argument("--incognito")Next we create a new instance of Chrome.
browser = webdriver.Chrome(executable_path='/Library/Application Support/Google/chromedriver', chrome_options=option)One thing to note is that the executable_path is the path that points to where you downloaded and saved your ChromeDriver.
Make The Request
When making the request we need to consider the following:
- Pass in the desired website url.
- Implement a Try/Except for handling a timeout situation should it occur.
In our case we are using a Github user profile as the desired website url:
browser.get(“https://github.com/TheDancerCodes")Next we specify a timeout period and the Try/Except:
# Wait 20 seconds for page to load
timeout = 20try:
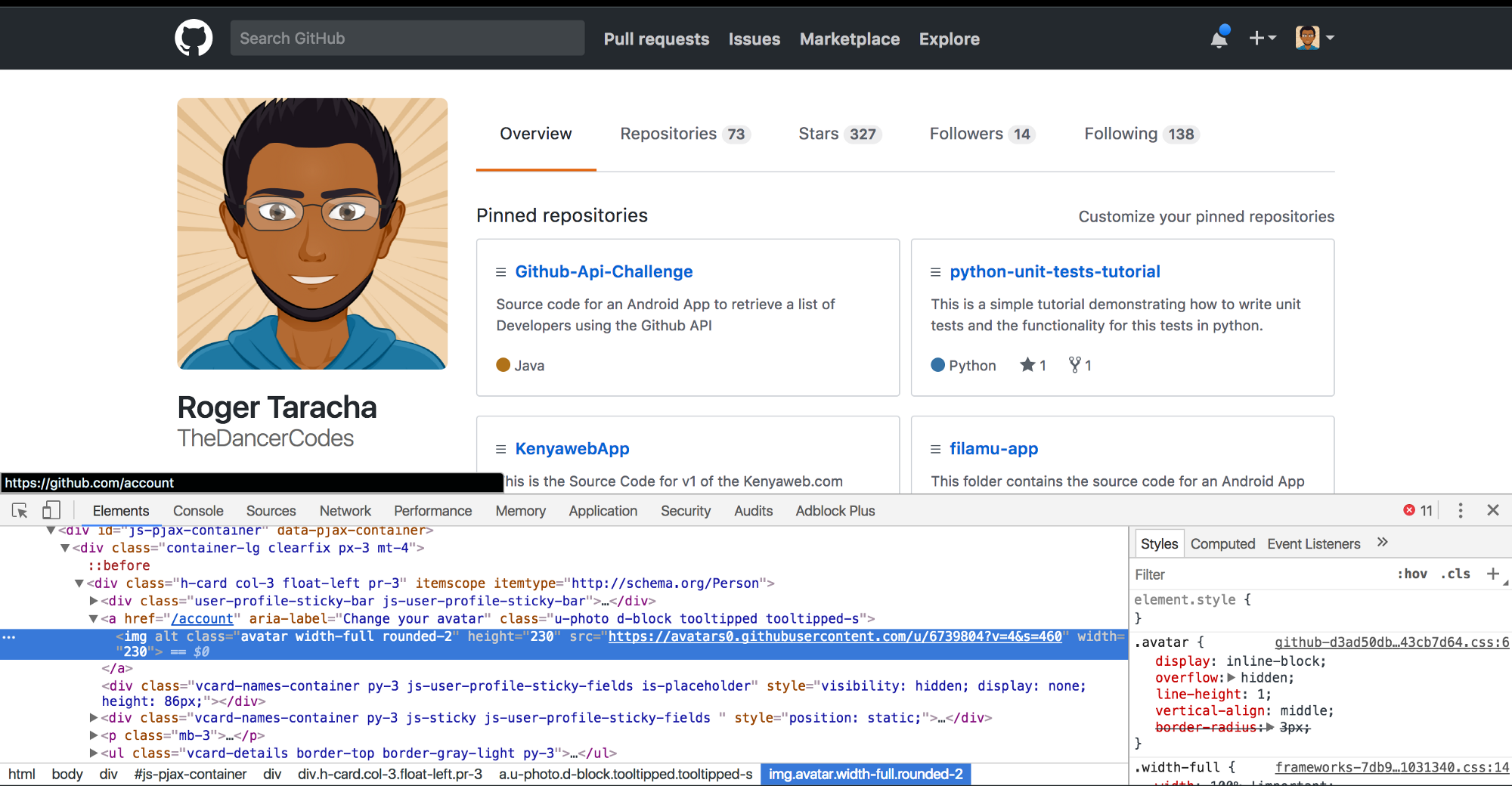
WebDriverWait(browser, timeout).until(EC.visibility_of_element_located((By.XPATH, "//img[@class=’avatar width-full rounded-2']")))except TimeoutException:
print(“Timed out waiting for page to load”)
browser.quit()NB: We wait until the final element [the Avatar image] is loaded.
The assumption is that if the Avatar is loaded, then the whole page would be relatively loaded as it is among the last things to load.
Get The Response
Once we make a request and it is successful we need to get a response. We will break the response into 2 and combine it at the end. The response is the title and language of the pinned repositories of our Github profile.
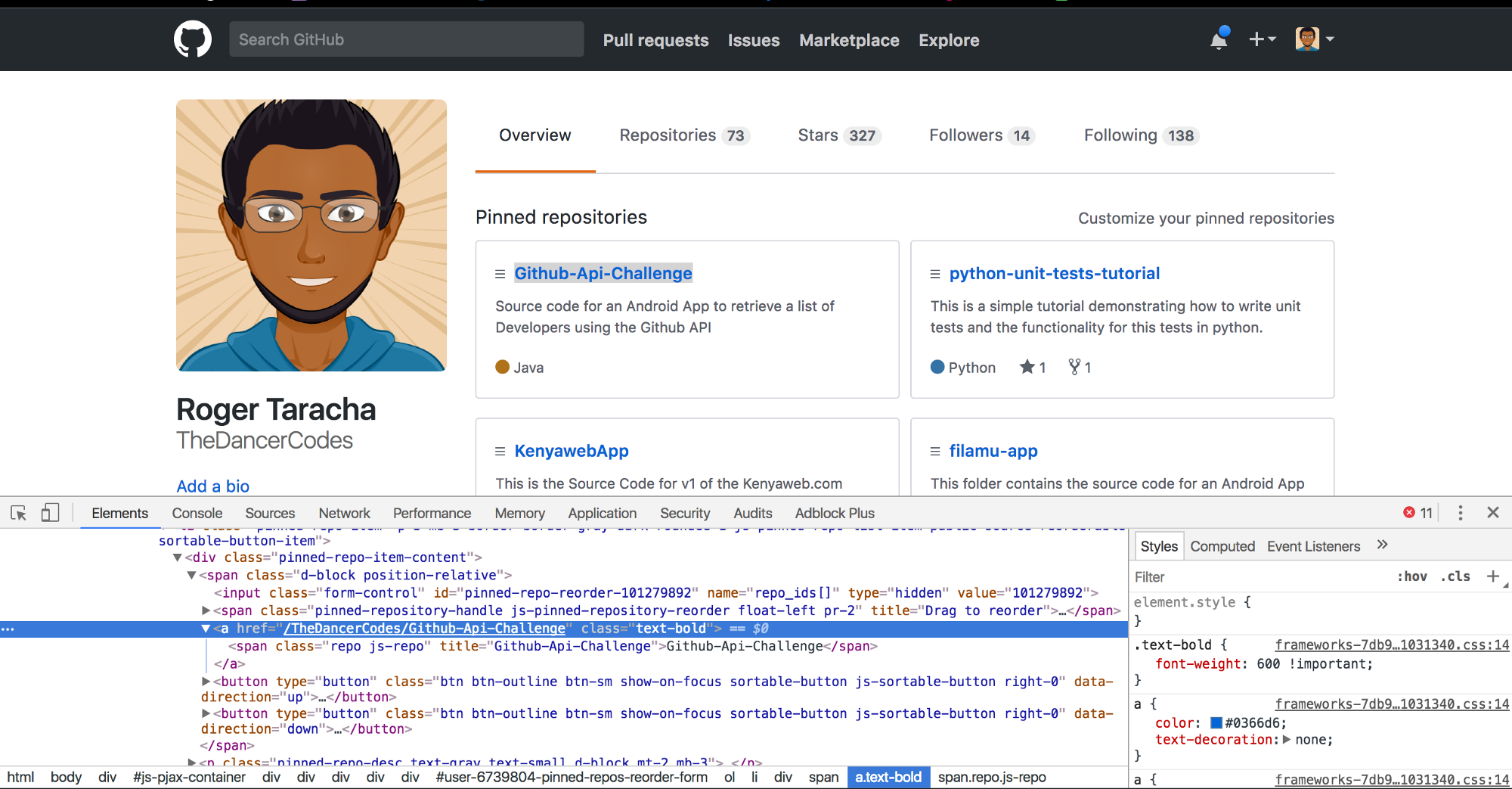
Lets start by getting all titles for the pinned repositories. We are not just getting pure titles but we are getting a selenium object with selenium elements that include the titles.
# find_elements_by_xpath returns an array of selenium objects.
titles_element = browser.find_elements_by_xpath(“//a[@class=’text-bold’]”)
# use list comprehension to get the actual repo titles and not the selenium objects.
titles = [x.text for x in titles_element]
# print out all the titles.
print('titles:')
print(titles, '\n')NB: The <a> tag and its class structure is the same for all the titles of the pinned repositories hence we can find all the elements using this structure as a reference.
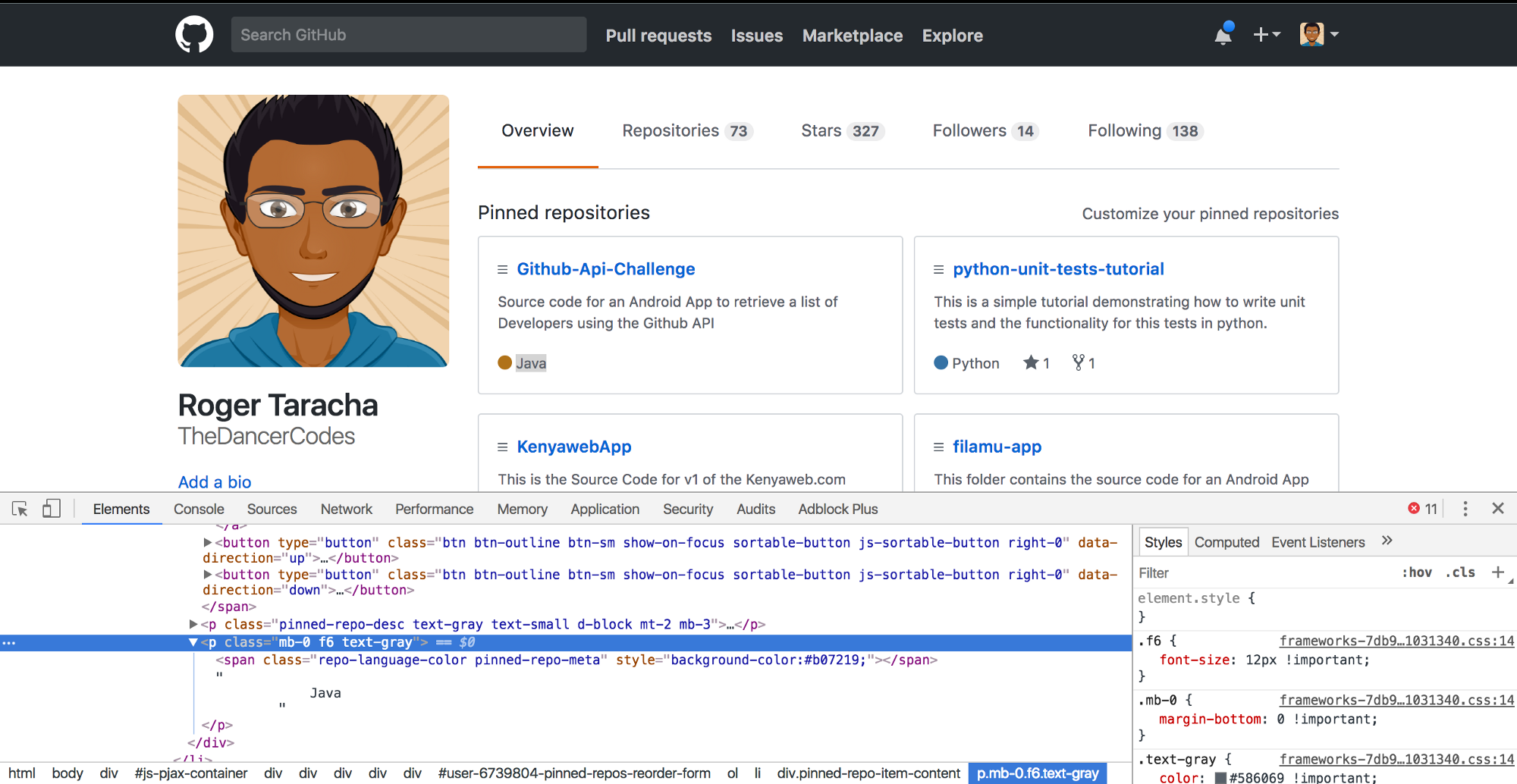
We will now get all the languages for the pinned repositories. It is similar to what we have above for the titles.
language_element = browser.find_elements_by_xpath(“//p[@class=’mb-0 f6 text-gray’]”)
# same concept as for list-comprehension above.
languages = [x.text for x in language_element]
print(“languages:”)
print(languages, ‘\n’)NB: The <p> tag and itsclass structure is the same for all the languages of the pinned repositories hence we can find all the elements using this structure as a reference.
Combine the responses using zip function
The final step is to pair each title with its corresponding language and then print out each pair. We achieve this using the zip function which matches the two elements from the 2 different arrays, maps them into tuples and returns an array of tuples.
for title, language in zip(titles, languages):
print(“RepoName : Language”)
print(title + ": " + language, '\n')Run the program
Finally execute the program by running it directly in your IDE or by using the following command:
$ (webscraping_example) python webscraping_example.pyAs the program runs it should launch the Chrome browser in incognito mode with the message “Chrome is being controlled by automated test software”.
On the terminal or in your IDE, you should see the printed out response in this format:
TITLES:
['Github-Api-Challenge', 'python-unit-tests-tutorial', 'KenyawebApp', 'filamu-app']
LANGUAGES:
['Java', 'Python 1 1', 'Java', 'Java']
RepoName : Language
Github-Api-Challenge: Java
RepoName : Language
python-unit-tests-tutorial: Python 1 1
RepoName : Language
KenyawebApp: Java
RepoName : Language
filamu-app: JavaYou now have the power to scrape!
You now have the foundational skills necessary to scrape websites.
Original article :
Introduction to Web Scraping using Selenium